Recommendation System for SF Bay Area Bike Share Program
Problem Statement
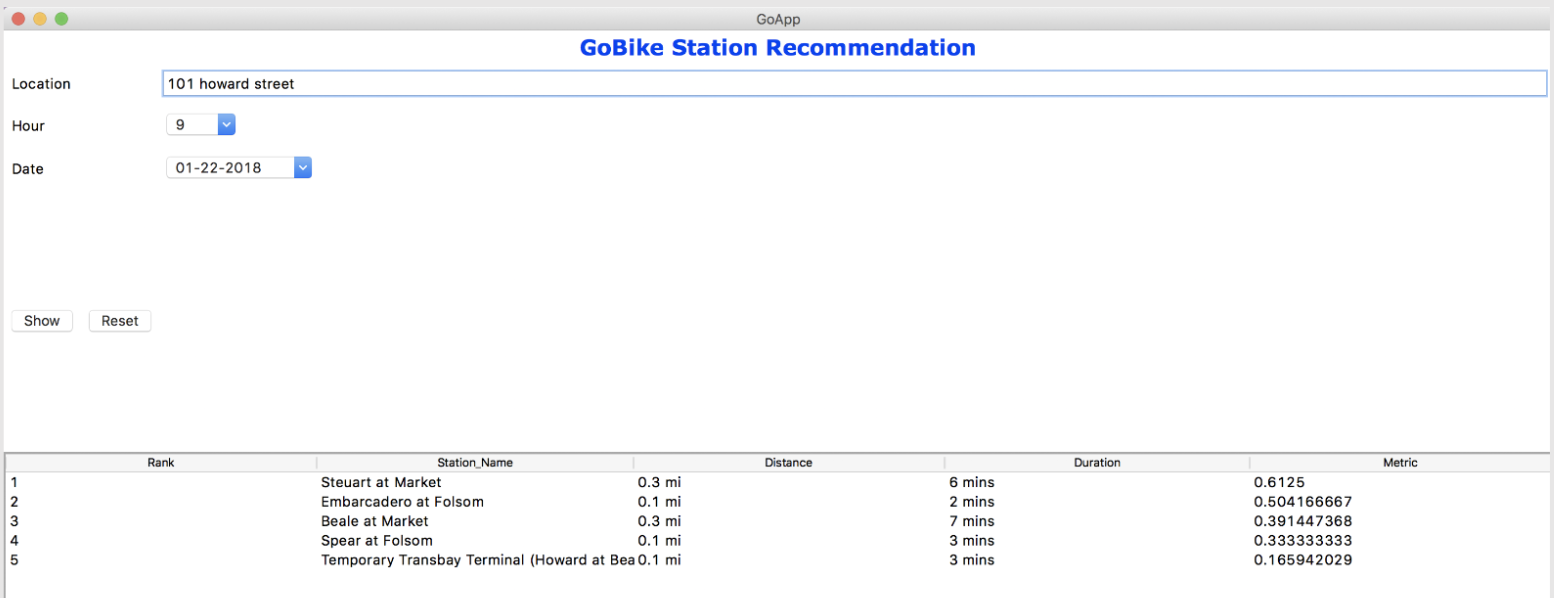
Given the shortage of bikes in San Francisco Bay Area, there is a need to optimize the probability of availing bikes at any of the nearest Ford GoBike stations. With the existing Ford GoBike app, real-time bike availability information can be tracked, however, a tool is needed to plan future rides.
The recommendation system should find a near station with high probability of bike availability in near future for future rides based on predictions of traffic and bike availability.
Motivation
This project was done as part of a class project for Distributed Data Systems at USF. We were learning Spark, associated libraries such as SparkSQL, SparkML and NoSQL databases such as MongoDB. We wanted to build a distributed data pipeline for the problem, and use machine learning algorithms to predict bike availability and traffic, and use that information to recommend a near bike station to a user based on his location and expected time of use of bike.
Implementation
A data pipeline was created by storing data in S3 buckets and querying through SparkSQL on AWS EC2 instance. Generalized linear regression and random forest regression models were used respectively to predict traffic and bike availability.